# Addition
16+32[1] 48Hier finden Sie die Aufgaben zu den einzelnen Kapiteln.
Diese Übungen finden sich auch in Kapitel 1.
File > New File > R Script)
# Angewandte Datenverarbeitung und Visualisierung - Woche 1 (17.04.2023)here-Paket (in der Konsole).here() (in Ihre R-Skript mit Strg+/Cmd+Eingabe). Was geschieht in der Konsole?# Addition
16+32[1] 48# Multiplikation
16*32[1] 512# Subtraktion
16-32[1] -16# Division
16/32[1] 0.5Cmd/Strg-Eingabe, um sie auszuführen. Was passiert?Speichern Sie die Werte 16 und 32 als Objekte namens x bzw. y.
Versuchen Sie, die Funktion mean() mit Ihren gespeicherten Variablen (x und y) als “verkettete” Argumente auszuführen (d.h., mit c()).
Machen Sie dasselbe mit der Funktion sum(). Was passiert, wenn Sie c() nicht verwenden?
vec1, der die Werte 12, 183, 56, 25 und 18 enthältvec2, der die Werte 8, 5, 1, 6 und 8 enthältvec3 that contains the values 28, 54, 10, 13, 2, and 81vec1.vec2. Wie unterscheidet sich das Ergebnis von dem, das Sie für vec1 allein erhalten haben?vec1 und vec3 zu finden?Diese Übungen finden sich auch in Kapitel 2.
Reproduzieren Sie unser Histogramm als Dichte-Diagramm, indem Sie geom_histogram() durch geom_density() ersetzen.
Erstellen Sie ein Balkendiagramm, das die Anzahl der Beobachtungen pro Wortklasse zeigt (Hinweis: Sie benötigen die Variable Class aus unserem Datensatz).
Drucken Sie Ihren Dichteplot und Ihren Klassen-Balkenplot übereinander mit Hilfe des patchwork Pakets
position = "dodge"):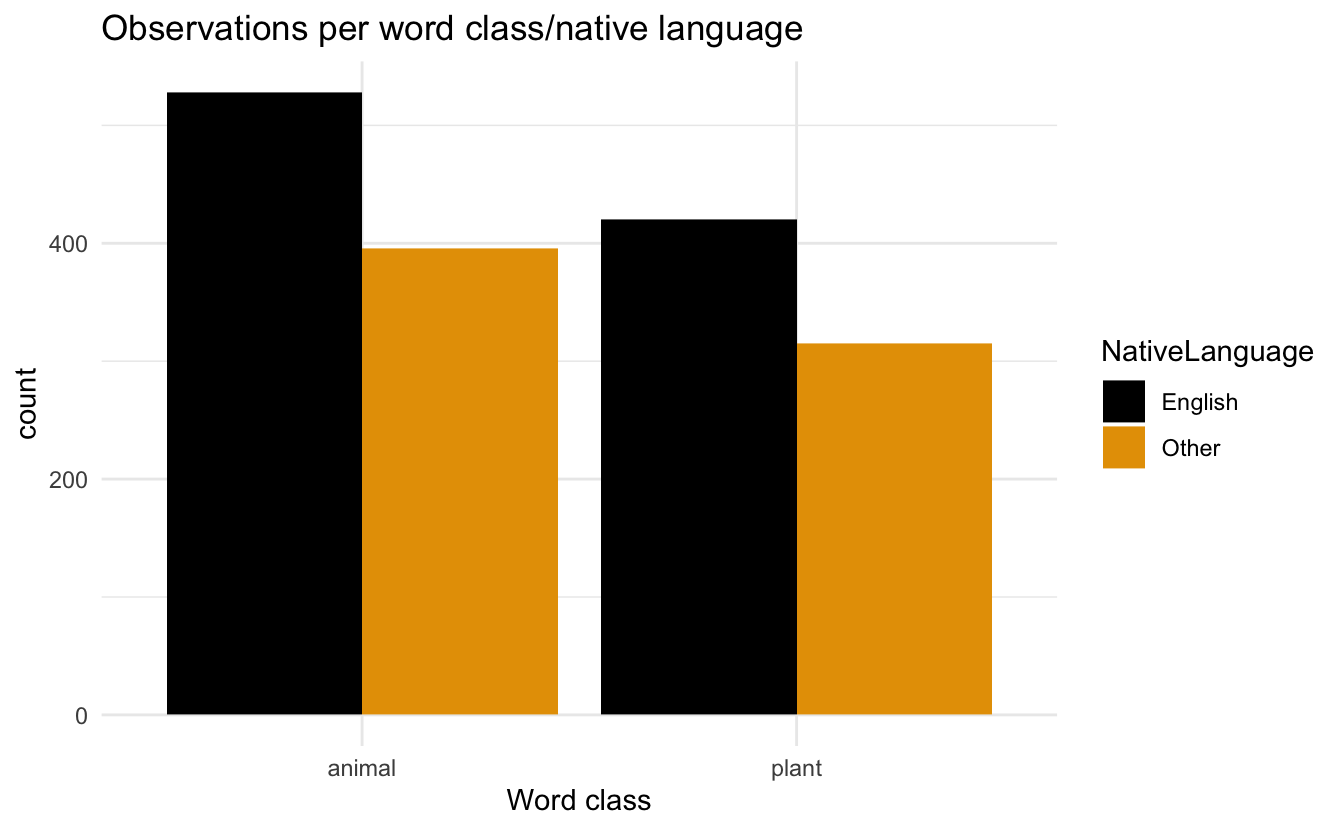
Diese Übungen finden sich auch in Kapitel 3.
Konsole aus: RStudio.Version()$version
2022.07 oder höher ist, können Sie Quarto benutzenHelp > Check for updatesFile > New Document > Quarto Document
03-quarto
in der YAML…
title)Autor: "vorname nachname" (siehe Beispiel unten)toc), indem du format so änderst, dass es wie folgt aussieht:---
title: "Quarto - Woche 3"
author: "Vorname Nachname"
format:
html:
toc: true
---Rendern nun das Dokument. Sehen Sie Ihre Änderungen?
Fügen Sie Ihrem Dokument einige Überschriften und Texte hinzu, die das Format und die Struktur von Quarto-Dokumenten beschreiben. Fügen Sie beispielsweise eine Überschrift mit dem Titel “YAML” ein, die kurz beschreibt, wie YAML formatiert ist.
Fügen Ihrem .qmd Dokumententext eine Textformatierung hinzu.
Fügen eine Aufzählungsliste hinzu
Fügen eine nummerierte Liste hinzu
Rendern Sie das Dokument. Hat es geklappt?
.qmd Datei hinzu
## Addition)Erinnern Sie sich, dass wir letzte Woche die Funktion c() (EN: concatenate) gesehen haben, die mehrere Werte kombiniert (z.B. mean(c(3,4,25)) ergibt den Mittelwert von 3,4 und 25)
Objektname <- c(...))echo: false und rendern das Dokument. Was ändert sich?echo: true, aber eval: false. Rendern das Dokument. Was ändert sich?html in der YAML durch revealjs. Rendert das Dokument.
format auf pdf. Rendert das Dokument.
pdf durch den Buchstaben l zu ersetzen. R schlägt eine Vervollständigung vor, welche ist es? Wähle sie aus und rendere das Dokument.html. Rendert das Dokument.revealjs dort?Diese Übungen finden sich auch in Kapitel 4. Befolgen Sie die Einrichtung aus diesem Kapitel, um diese Übungen zu bearbeiten Kapitel 4.1.
df_lexdec für Zeilen drucken, die jede der folgenden Bedingungen erfüllen:RT) waren größer als 500ms und kleiner als 550msWord) pear, elephant oder tortoise stammenRT) (kleinste bis größte)arrange()) df_lexdec in absteigender Reihenfolge (desc()), um die Versuche mit den längsten Reaktionszeiten zu finden.df_rz, das df_lexdec enthält, und dann (|>):
mutate()) namens rz_s (siehe ex. 4.4: RT durch 1000 dividieren), und dann (|>)select()) Sie die Variablen Subject, NativeLanguage, Word, rz_s, Length, und Frequency, und dann (|>)rz_s_laenge (mit mutate()), die rz_s geteilt durch Length ist, und dann (|>)
Length gesetzt (mit relocate()), und dann (|>)rename()`) Sie diese Variablen in Englisch um, so dass sie in Deutsch (und mit Kleinbuchstaben) sindhead() verwenden).Diese Übungen finden sich auch in Kapitel 5. Befolgen Sie die Einrichtung aus diesem Kapitel, um diese Übungen zu bearbeiten Kapitel 5.1.
AgeSubject (x-Achse) nach CV (Facetten).RTlexdec (x-Achse) durch RTnaming (y-Achse) dar. Übertragen Sie CV auf Farbe (colour) und Form (shape). Fügen Sie geeignete Beschriftungen hinzu.
ggsave()Diese Übungen finden sich auch in Kapitel 6 Befolgen Sie die Einrichtung aus diesem Kapitel, um diese Übungen zu bearbeiten Kapitel 6.1.
Nun wollen wir üben, das Paket readr zu benutzen und mit unseren Daten zu arbeiten.
readr Funktionen|” getrennt sind?read_csv() und read_tsv() gemeinsam?;) als Trennzeichen einzulesen?Laden Sie die Datei groesse_geburtstag.csv erneut. Benutzen Sie Pipes, um auch die Funktion clean_names zu benutzen, und um die folgenden Änderungen im Objekt df_groesse vorzunehmen.
l1 in einen Faktor.grosse in groessewas_fur_ein_haustier in haustierartdf_groesse-Datensatz, das die Beziehung zwischen unserem Geburtsmonat und unseren Größe visualisiert (es macht keinen Sinn, dies zu vergleichen, aber es ist nur eine Übung). Suchen Sie Ihren Geburtstag in der Grafik. Stellen Sie die Farbe und die Form so ein, dass sie “L1” entsprechen. Fügen Sie einen Titel für die Grafik hinzu.haustierart. Um die Visualisierung zu erleichtern, fügen Sie haustierart auch als fill in die Ästhetik ein. Geben Sie geeignete Diagramm- und Achsentitel mit lab(...) an. What is the most frequent pet type?Diese Übungen begleiten Kapitel 7. Um diese Aufgaben zu erledigen, müssen Sie die Pakete tidyverse, janitor und here laden, sowie den Datensatz languageR_english.csv, wie es in Kapitel 7.1.
152, 19, 1398, 67, 2111, ohne die Funktion sd() zu benutzen.
c()mean()x^2 berechnet das Quadrat eines Wertes (hier, x)sqrt() berechnet die Quadratwurzellength() liefert die Anzahl der Beobachtungen in einem Vektorsd(), um die Standardabweichung der obigen Werte zu drucken. Haben Sie es richtig gemacht?summary()summarise, um den Mittelwert, die Standardabweichung und die Anzahl der Beobachtungen für rt_naming im df_eng Datenrahmen zu drucken.
NA) entfernen?.by() hinzu, um die mittlere Reaktionszeit der Benennungsaufgabe (rt_naming) pro word_category zu ermitteln
Diese Übungen begleiten Kapitel 8. Um diese Aufgaben zu erledigen, müssen Sie die Pakete tidyverse, janitor und here laden, sowie den Datensatz languageR_english.csv, wie es in Kapitel 8.1.
fig_boxplot, der ein Boxplot der df_eng Daten ist, mit:
age_subject auf der x-Achsert_naming auf der y-Achseage_subject als colour oder fill (wähle eine, es gibt keine falsche Wahl)word_category in zwei Facetten mit facet_wrap() aufgetragentheme_-Einstellung (z.B. theme_bw(); für weitere Optionen siehe hier)rt_naming aus df_eng verwenden.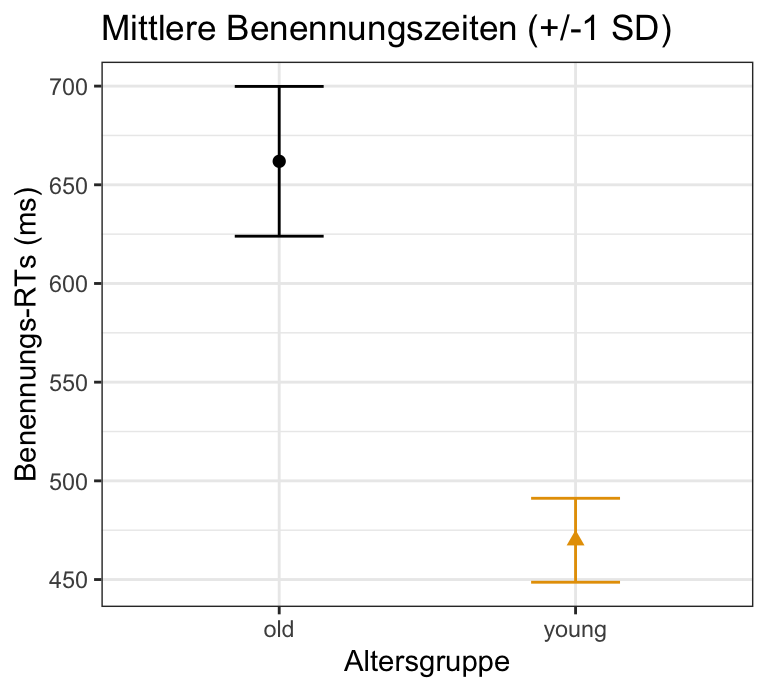
patchwork, um Ihren Boxplot und Ihre Fehlerbalkenplots nebeneinander darzustellen. Es sollte ungefähr so aussehen wie Abbildung A.3. Hinweis: Wenn Sie die “tag-level” (“A” und “B”) zu den Plots hinzufügen möchten, müssen Sie + plot_annotation(tag_level = "A") aus patchwork hinzufügen.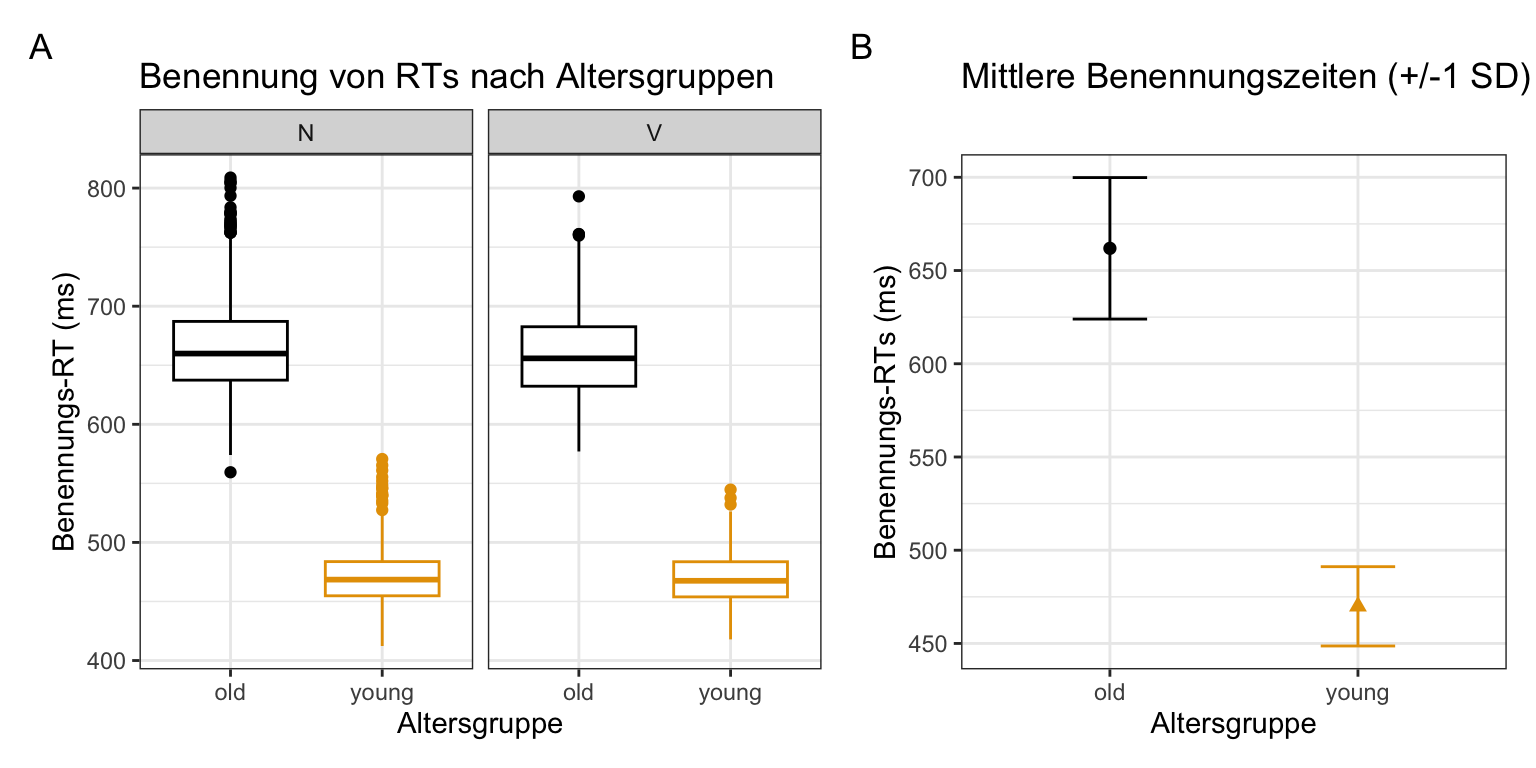
patchwork
Diese Übungen begleiten Kapitel 9. Um diese Aufgaben zu erledigen, müssen Sie die Pakete tidyverse, janitor und here laden, sowie den Datensatz languageR_english.csv (df_eng), wie es in Kapitel 9.1.
pivot_longer() |> summarise()df_eng_long (wie in Kapitel 9.5.1). Verwenden Sie dann die Funktion summarise(), um die folgenden zusammenfassenden Statistiken zu erstellen:# A tibble: 2 × 3
response mean sd
<chr> <dbl> <dbl>
1 rt_lexdec 708. 115.
2 rt_naming 566. 101.Hinweis: Müssen Sie NA entfernen (wir haben im letzten Kapital gesehen, wie man das macht)?
pivot_wider()pivot_wider, um mit rt_naming neue Variablen zu erstellen: naming_old und naming_young, die die Reaktionszeiten beim Benennen für alte bzw. junge Teilnehmer enthalten. Hinweis: Sie müssen rt_lexdec entfernen. Speichern Sie den Datenrahmen als df_eng_wider als Objekt. Der resultierende Datenrahmen sollte 2284 Beobachtungen und 6 Variablen enthalten.df_eng_wider.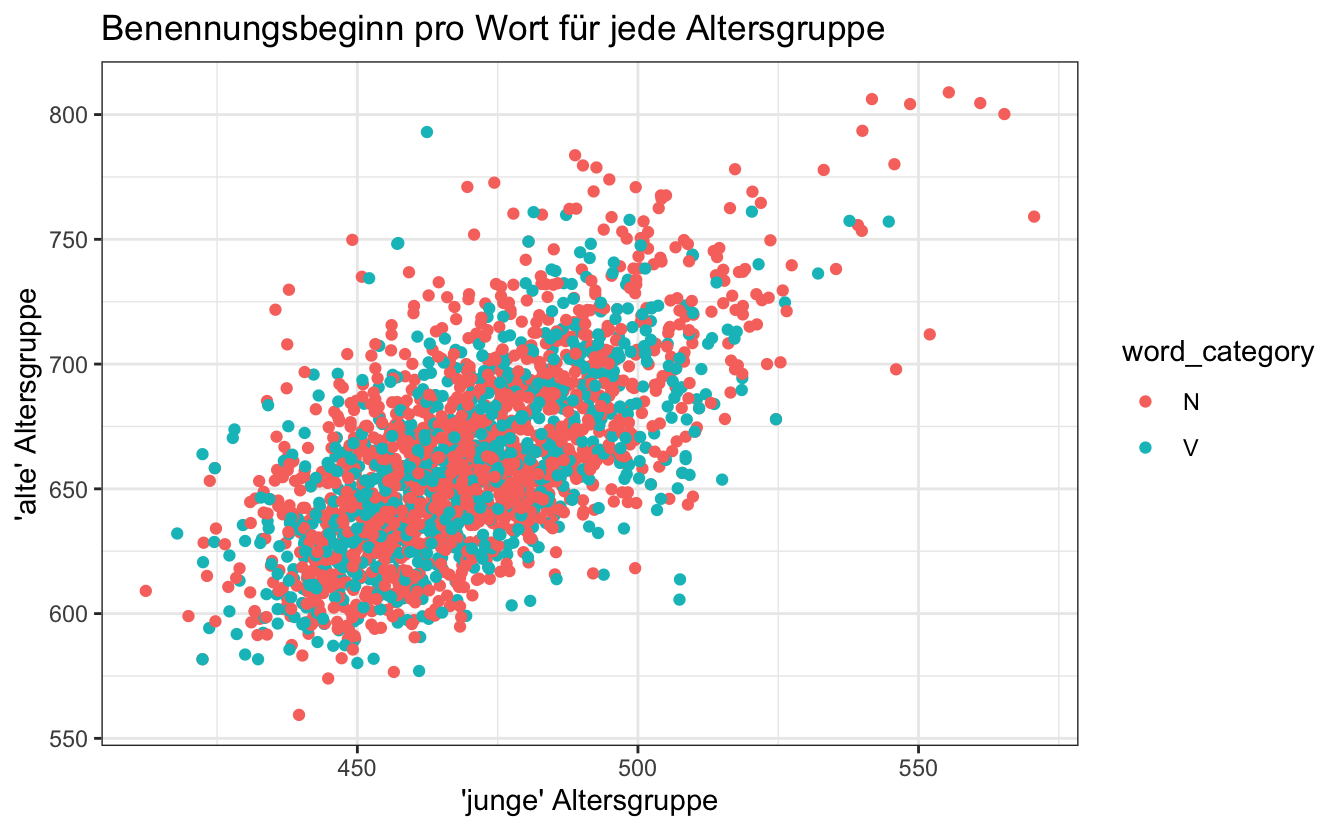
df_eng_wide-Datensatz, um Abbildung A.4 zu erstellen? Mit anderen Worten, warum ist df_eng_wide die geeignete Struktur, aber nicht df_eng_long für ein solches Streudiagramm?Diese Übungen begleiten Kapitel 10. Sie brauchen keine Pakete zu laden, da diese Übungen die Verwendung von Basis-R voraussetzen. Sie sollten jedoch tidyverse laden, wenn Sie den Beispielcode ausführen wollen.
tidyverse zur base RKonvertieren Sie den folgenden tidyverse-Code in Base R. Wir werden wieder den Datensatz languageR_english.csv verwenden.
df_eng <-
readr::read_csv(here::here("daten", "languageR_english.csv"))df_eng |>
select(Word, WrittenFrequency)# A tibble: 10 × 2
Word WrittenFrequency
<chr> <dbl>
1 doe 3.91
2 whore 4.52
3 stress 6.51
4 pork 5.02
5 plug 4.89
6 prop 4.77
7 dawn 6.38
8 dog 7.16
9 arc 4.89
10 skirt 5.93df_eng |>
filter(WrittenFrequency > 5.6)# A tibble: 10 × 7
AgeSubject Word LengthInLetters WrittenFrequency WordCategory RTlexdec
<chr> <chr> <dbl> <dbl> <chr> <dbl>
1 young stress 6 6.51 N 547.
2 young dawn 4 6.38 N 584.
3 young dog 3 7.16 N 527.
4 young skirt 5 5.93 N 536.
5 young are 3 11.3 N 611.
6 young pipe 4 6.00 N 563.
7 young guard 5 6.59 N 559.
8 young slope 5 5.80 N 633.
9 young pile 4 6.16 N 595.
10 young tide 4 6.08 N 598.
# ℹ 1 more variable: RTnaming <dbl>df_eng |>
filter(WrittenFrequency > 5.6 & AgeSubject == "old") |>
select(AgeSubject, Word, WrittenFrequency) # A tibble: 10 × 3
AgeSubject Word WrittenFrequency
<chr> <chr> <dbl>
1 old stress 6.51
2 old dawn 6.38
3 old dog 7.16
4 old skirt 5.93
5 old are 11.3
6 old pipe 6.00
7 old guard 6.59
8 old slope 5.80
9 old pile 6.16
10 old tide 6.08df_eng |>
ggplot() +
aes(x = WrittenFrequency, y = RTlexdec) +
geom_point()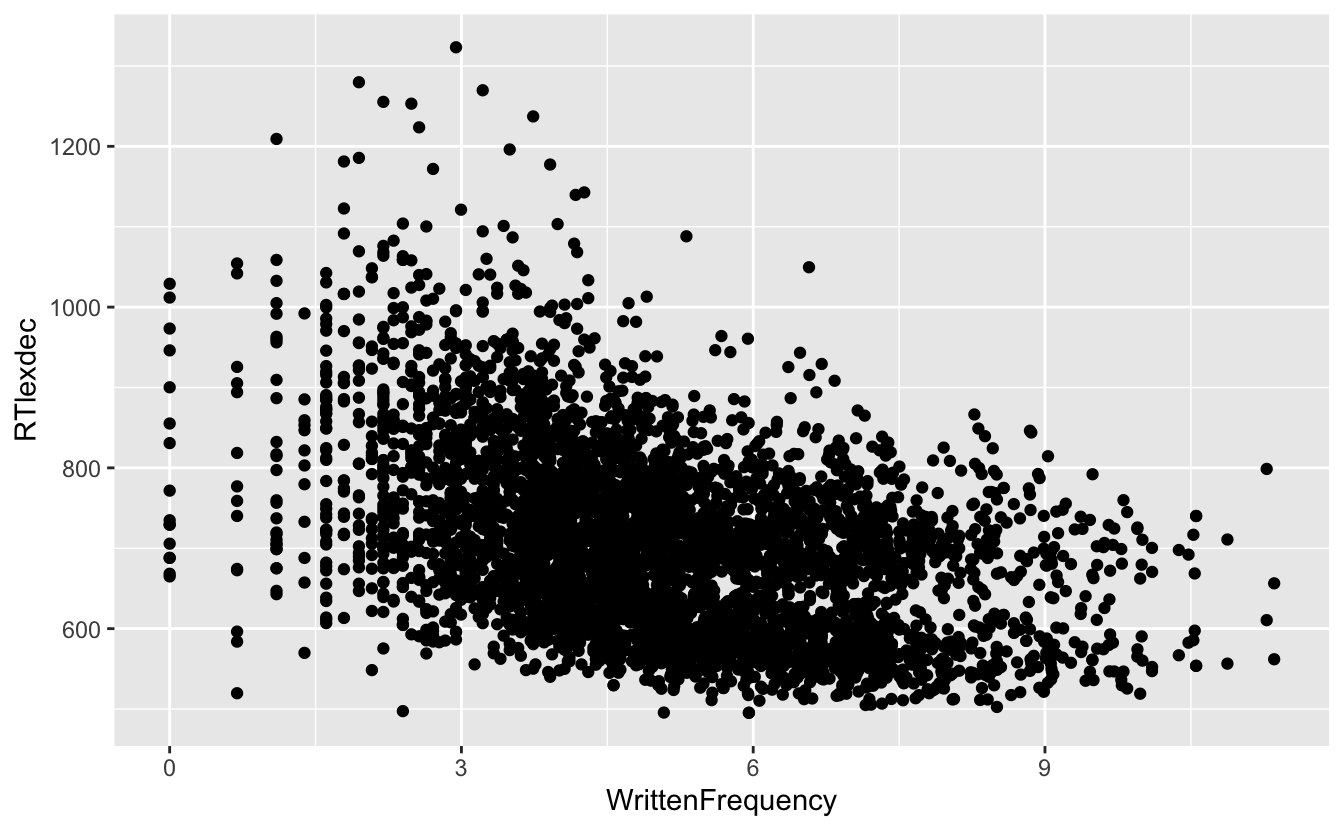
Wie ist Ihr Eindruck von Base R im Vergleich zu Tidyverse? Würden Sie, basierend auf dem, was Sie gesehen haben, das eine dem anderen vorziehen, oder würden Sie das eine nur in bestimmten Fällen vorziehen? Hier gibt es keine richtige Antwort.
Diese Übungen begleiten Kapitel 11. Um diese Aufgaben zu erledigen, müssen Sie die Pakete tidyverse, janitor, here, und patchwork laden, sowie den Datensatz languageR_english.csv (df_eng), wie es in Kapitel 11.1.
rt_naming (anstelle von rt_lexdec). Drucken der Plots nebeneinander mit patchwork.labs(), um Beschriftungen für den Titel, die x- und y-Achse und für die von Ihnen verwendete Ästhetik (Form, Farbe, etc.) hinzuzufügen, die in einer Legende resultieren. Dies sollte damit enden, dass der Titel der Legende auch einen eigenen Namen erhält.theme() mit Anpassungen für die Achsentitel, den Legendentitel und den Diagrammtitel. Sie können face, size, colour, family (d.h. Schriftart) ändern. Sie können ?theme in der Konsole eingeben oder googeln, um einige Ideen zu bekommen. Wenn Sie sich nicht kreativ fühlen, versuchen Sie einfach, eine der Anpassungen zu replizieren, die Sie in Abbildung 11.10 sehen