Reproducible analyses in R
What, Why, and How?
Tue Oct 8, 2024
How to practice Open Science
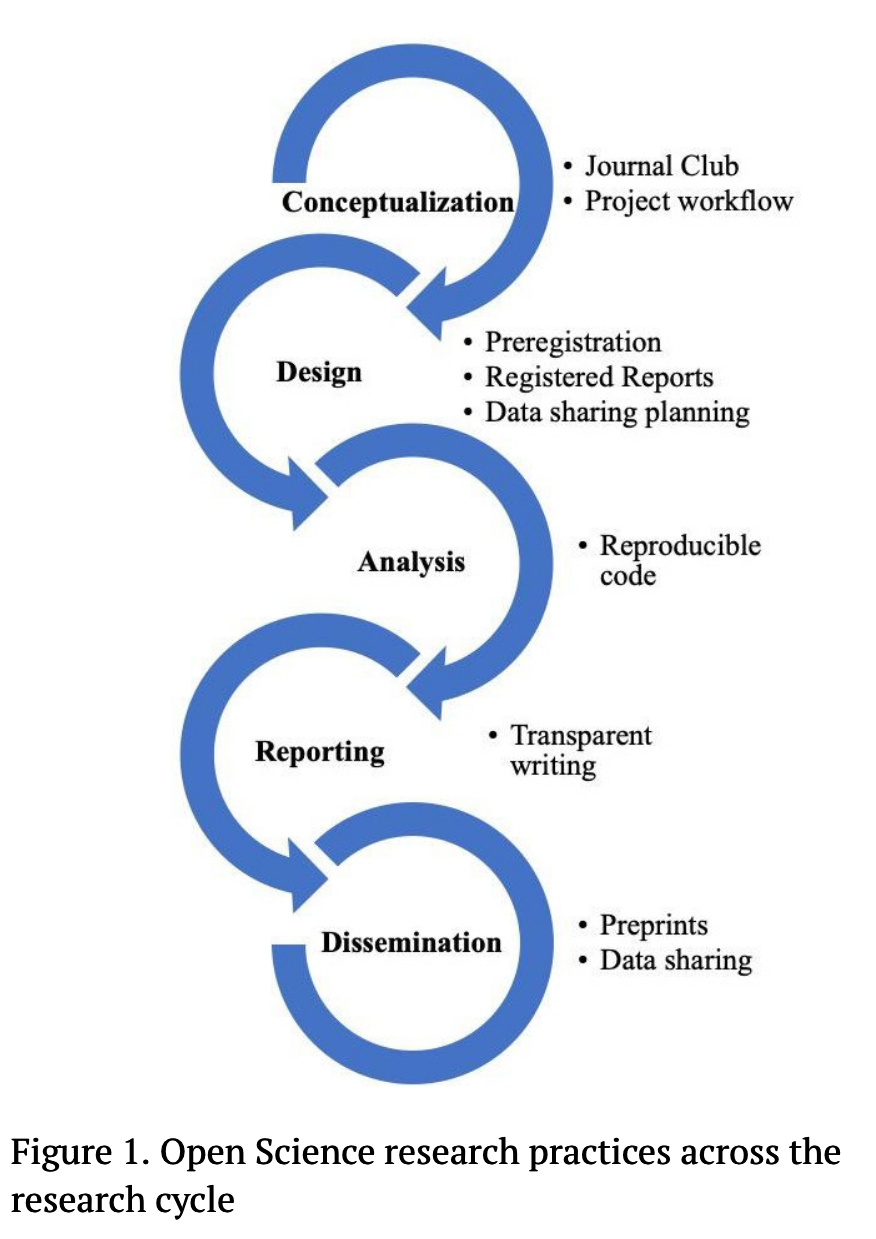
Figure 1 shows some suggestions from Kathawalla et al. (2021)
Open Science is not all-or-nothing
-
there are things I consider the bare minimum
- detailed experiment plan, ideally public
- openly available materials (e.g., stimuli)
- share code and data
the important thing is to do what you can
Which Open Science research practices in Figure 1 do you already practice? Are there any you’d like to start implementing?
Practice FAIR principles
- guidelines for sharing digital resources
- refers broadly to (meta)data, let’s extend them to analysis code

-
findable and accessible: where materials are stored
- in findable repositories
- that are accessible, i.e., do not require an account
-
interoperable and reusable: format of data (and code)
- the importance of future use
- and use beyond your precise computational environment
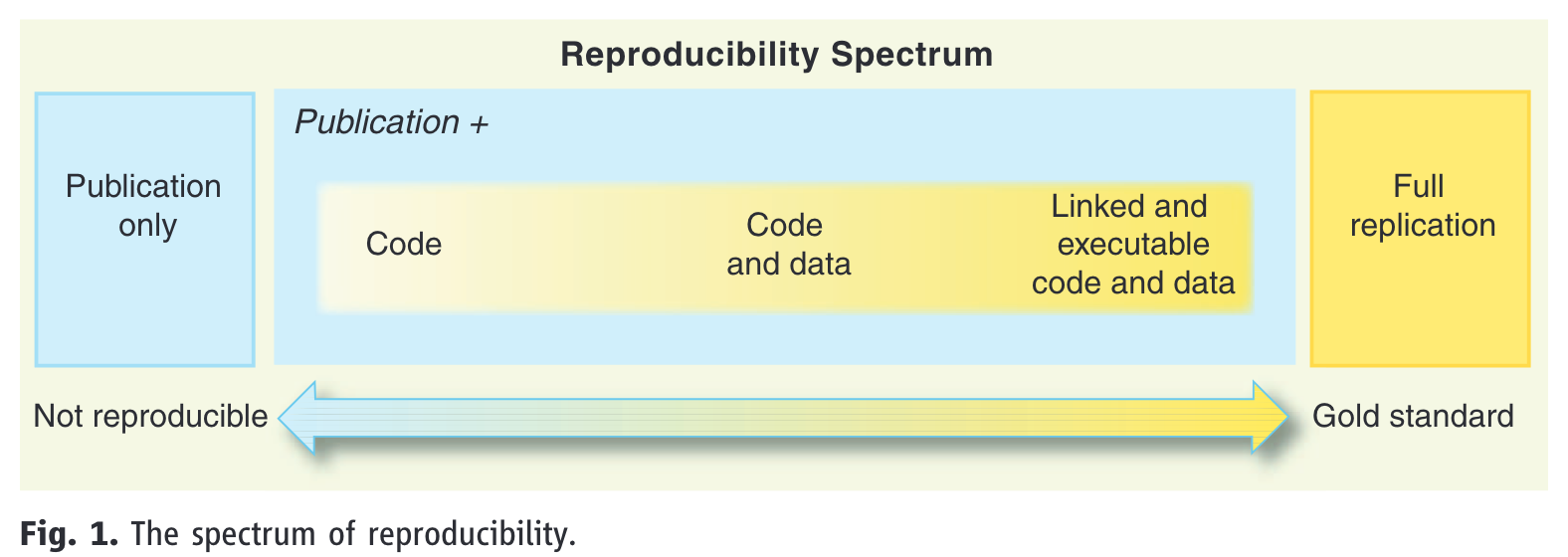
The reproducibility spectrum
- reproducibility is on a continuum, referred to as the reproducibility spectrum in Peng (2011) (Figure 3)
- linked means “all data, metadata, and code [is] stored and linked with each other and with corresponding publications” (Peng, 2011, p. 1227)
- executable is not explained, and is more difficult to guarantee long-term as it depends on software versions
- but at minimum we can assume it refers to code running on someone else’s machine
Reproducibility rates in linguistic research

- meta-analysis of 519 randomly sampled articles from various linguistic journales
- pre- and post-reproducibility crisis (2008/9, 2018/19) (Bochynska et al., 2023)
- differentiated between primary (collected for study) and secondary (pre-existing) data
- reported a post-RC increase in shared materials, data, and analyses
- but still low rates of each
- higher rates of secondary data sharing, presumably due to publicly available corpora
- data shared more often than analyses, pre- and post-RC
Journal of Memory and Language
- meta-analysis of articles from JML (Laurinavichyute et al., 2022)
- before and after an Open Science Policy was introduced in 2019
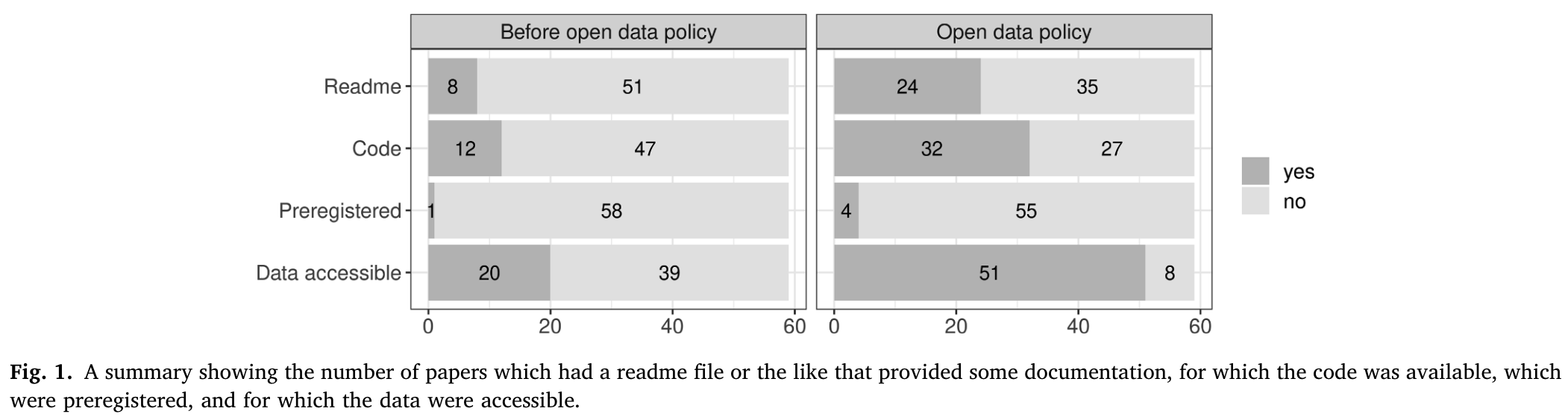
Figure 5: Source: Laurinavichyute et al. (2022), p. 5 (all rights reserved)
- code and data availability improved
- but reproducibility rate ranged from 34-56%, depending on criteria
- higher rates compared to field-wide meta-analysis (Bochynska et al., 2023)
References
Bochynska, A., Keeble, L., Halfacre, C., Casillas, J. V., Champagne, I.-A., Chen, K., Röthlisberger, M., Buchanan, E. M., & Roettger, T. B. (2023). Reproducible research practices and transparency across linguistics. Glossa Psycholinguistics, 2(1). https://doi.org/10.5070/G6011239
Bowers, J., & Voors, M. (2016). How to improve your relationship with your future self. Revista de Ciencia Política (Santiago), 36(3), 829–848. https://doi.org/10.4067/S0718-090X2016000300011
Corker, K. S. (2022). An Open Science Workflow for More Credible, Rigorous Research. In M. J. Prinstein (Ed.), The Portable Mentor (3rd ed., pp. 197–216). Cambridge University Press. https://doi.org/10.1017/9781108903264.012
Crüwell, S., Van Doorn, J., Etz, A., Makel, M. C., Moshontz, H., Niebaum, J. C., Orben, A., Parsons, S., & Schulte-Mecklenbeck, M. (2019). Seven Easy Steps to Open Science: An Annotated Reading List. Zeitschrift Für Psychologie, 227(4), 237–248. https://doi.org/10.1027/2151-2604/a000387
Kathawalla, U.-K., Silverstein, P., & Syed, M. (2021). Easing Into Open Science: A Guide for Graduate Students and Their Advisors. Collabra: Psychology, 7(1), 18684. https://doi.org/10.1525/collabra.18684
Knuth, D. (1984). Literate programming. The Computer Journal, 27(2), 97–111.
Nagler, J. (1995). Coding Style and Good Computing Practices. PS: Political Science & Politics, 28(3), 488–492. https://doi.org/10.2307/420315
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716. https://doi.org/10.1126/science.aac4716
Peng, R. D. (2011). Reproducible Research in Computational Science. Science, 334(6060), 1226–1227. https://doi.org/10.1126/science.1213847
Wickham, H., Çetinkaya-Rundel, M., & Grolemund, G. (2023). R for Data Science (2nd ed.). https://r4ds.hadley.nz/
Wilson, G., Bryan, J., Cranston, K., Kitzes, J., Nederbragt, L., & Teal, T. K. (2017). Good enough practices in scientific computing. PLOS Computational Biology, 13(6), e1005510. https://doi.org/10.1371/journal.pcbi.1005510
