
Publishing our project and conducting a code review
Reproducing analyses from a persistant public repository
Thu Oct 17, 2024
Open and FAIR data
- recall the FAIR principles we discussed at the beginning of term
- data should be Findable, Accessible, Interoperable, and Reusable
- we’re extending these principles to our analyses as well
- so far, our data and analyses are stored locally on our machines
- we need to share them with persistent public storage
- e.g., GitHub or GitLab, the Open Science Framework (OSF) or Zenodo
Download OSF repo
- let’s start by downloading our OSF repo
- from the project overview page, go to the ‘Files’ pane
- click on ‘OSF Storage (Germany - Frankfurt)’
- Click ‘Download as zip’ button and store somewhere useful/rename as needed
Reproducibility spectrum
- reproducibility is on a continuum, referred to as the reproducibility spectrum in Peng (2011) (Figure 3)
- linked means “all data, metadata, and code [is] stored and linked with each other and with corresponding publications” (Peng, 2011, p. 1227)
- executable is not explained, and is more difficult to guarantee long-term as it depends on software versions
- but at minimum we can assume it refers to code running on someone else’s machine
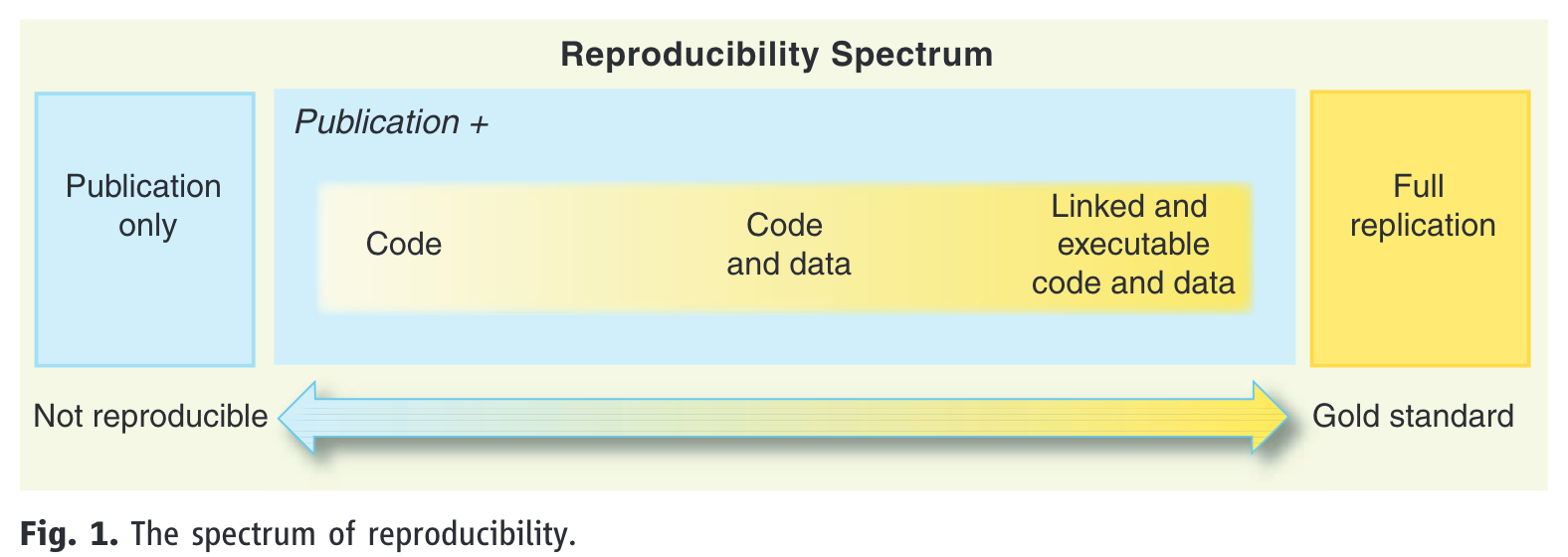
Figure 3: Source: Peng (2011)
Reproducibility iceberg

- a more detailed description of this continuum is givin in Rodrigues (2023)’s reproducibility iceberg (Figure 4)
- our project is currently somewhere near the top-middle of the iceberg
- we’re not using GitHub, with is a developer platform and useful for version control and is beyond the scope of this course
- GitHub and OSF serve some overlapping, but not identical, purposes
- importantly, the iceberg explicitly mentioned the
renvpackage- this reminds us that we should be sharing some files generating by
renv
- this reminds us that we should be sharing some files generating by
.Rprofile in Finder
Some files are usually invisible on a Mac, such as those that start with dot (like .Rprofile). This makes it difficult to simply drag and drop the .Rprofile file to the OSF. To make such files viewable in Finder, navigate to the relevant project folder and use the keyboard shortcut Ctrl + Shift + Dot. These files will then appear greyed out.
Ctrl + Shift + Dot to view hidden files on a Mac
OSF repo structure
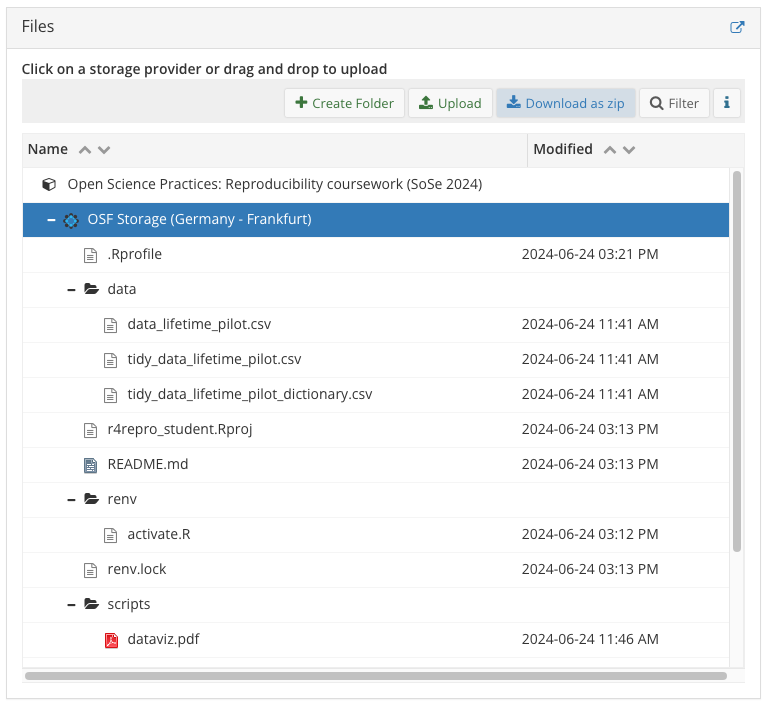
Figure 6: Your OSF should now look like this
References
DeBruine, L. (2022). Intro to code review. https://debruine.github.io/code-review/
Peng, R. D. (2011). Reproducible Research in Computational Science. Science, 334(6060), 1226–1227. https://doi.org/10.1126/science.1213847
Rodrigues, B. (2023). Building reproducible analytical pipelines with R.
