Reproducibility in linguistic research and R
What, Why, and How?
Wed Aug 21, 2024
Why do Open Science?
- open science is good science
- it encourages organisation and planning
- helpful for future you
- increases transparency
- without transparency we cannot inspect evidence ourselves
- or ensure the claims match the evidence
- makes our work more robust
- so future work stands on solid ground
- not all-or-nothing
- there are things I consider the bare minimum
- detailed experiment plan, ideally public
- openly available materials (e.g., stimuli)
- share code and data
- the important thing is to do what you can
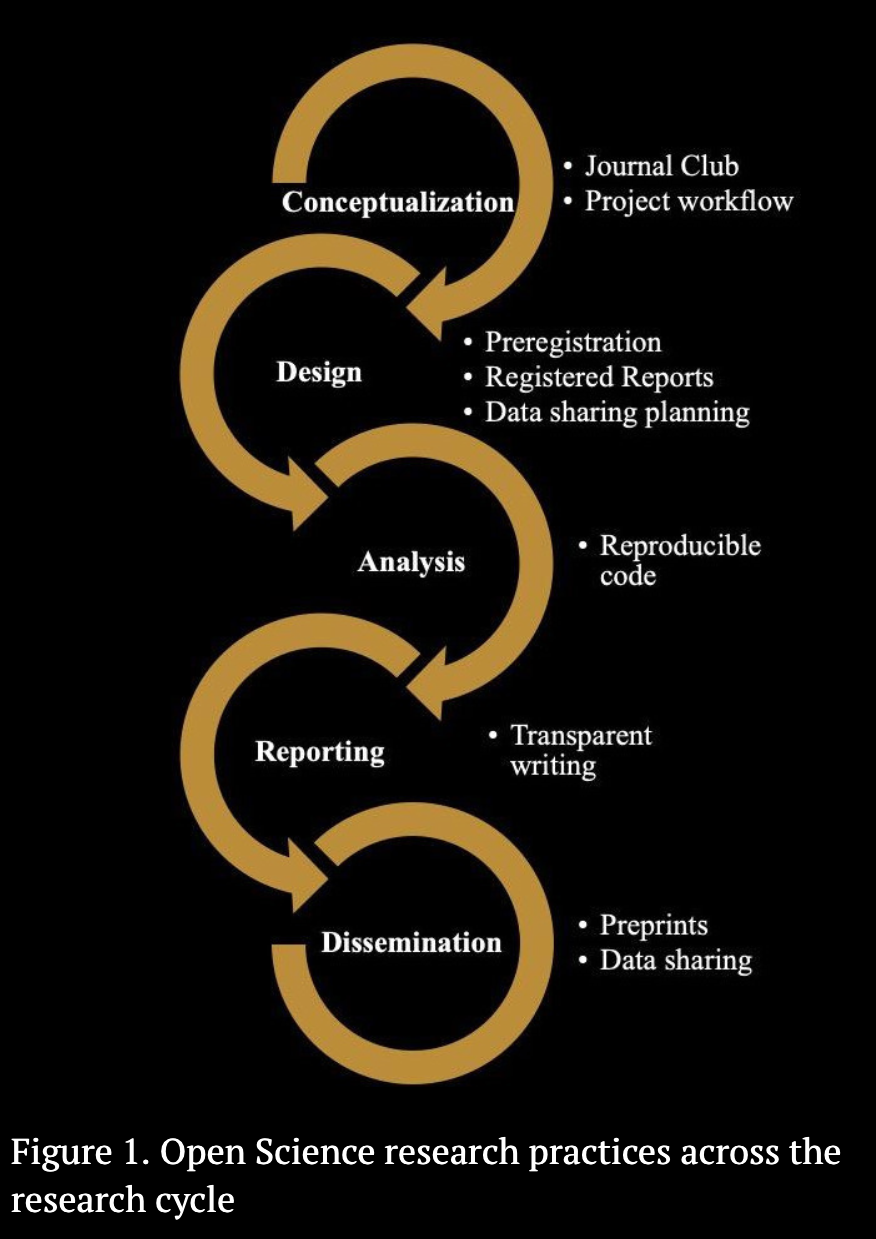
- which Open Science research practices in Figure 1 are relevant related to reproducibility?
Practice FAIR principles
- guidelines for sharing digital resources
- refers broadly to data, but we’ll consider it in terms of analyses

- findable and accesssible refer to where materials are stored
- in findable repositories
- that are accessible, i.e., do not require an account
- interoperable and reusable emphasise the format of data (and code)
- the importance of future use
- and use beyond your precise computational environment
The reproducibility spectrum
- reproducibility is on a continuum, referred to as the reproducibility spectrum in Peng (2011) (Figure 3)
- linked means “all data, metadata, and code [is] stored and linked with each other and with corresponding publications” (Peng, 2011, p. 1227)
- executable is not explained, and is more difficult to guarantee long-term as it depends on software versions
- but at minimum we can assume it refers to code running on someone else’s machine

Figure 3: Source: Peng (2011)
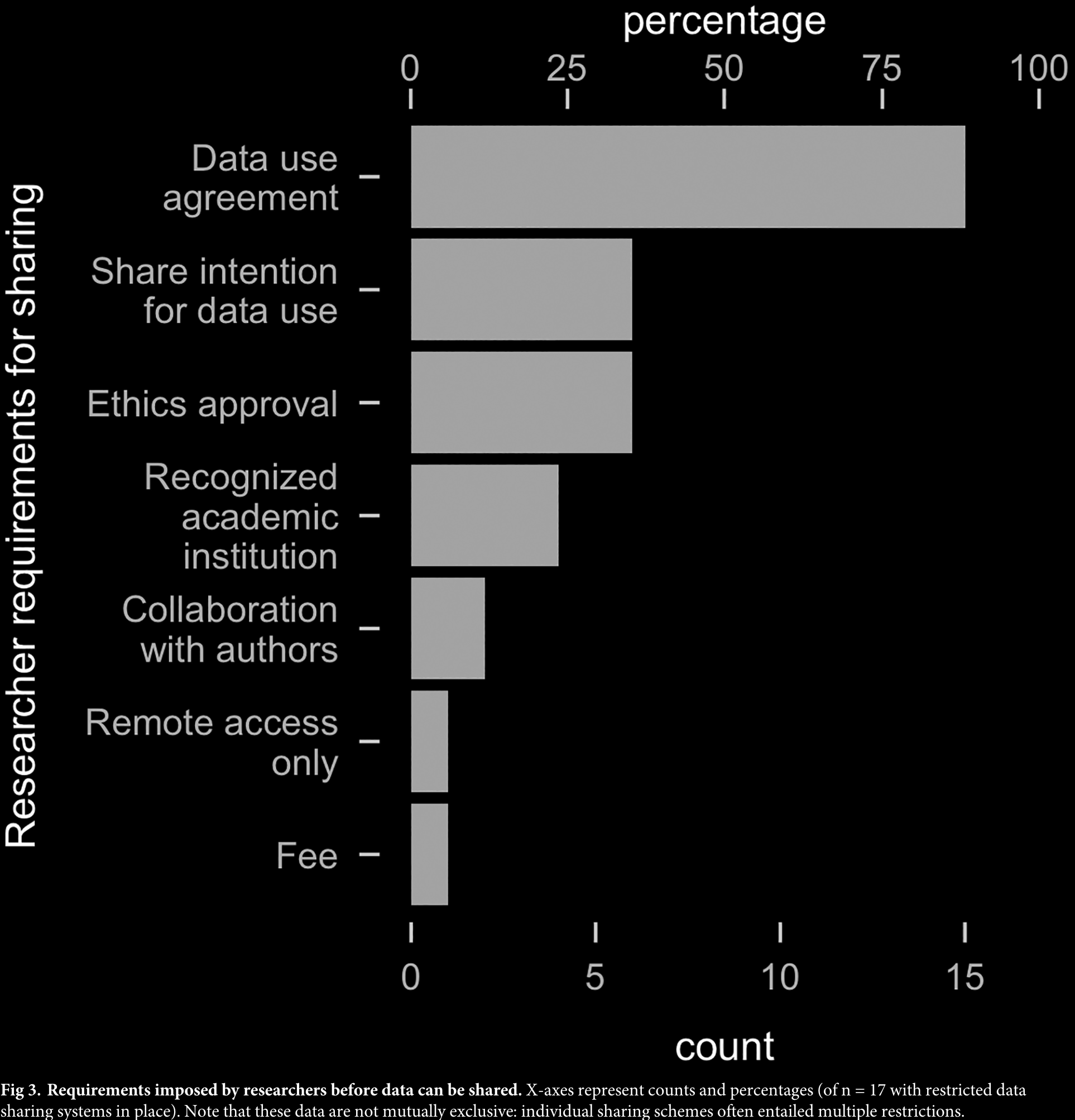
Data and code availability
- “data available upon (reasonable) request”
- generally not true
- data was not available in 68% of the most cited psychology studies (2006-2016) (Hardwicke & Ioannidis, 2018)
- a further 18% were available with restrictions
- only 11% available without restriction
- data alone is not sufficient
- ‘Data Analysis’ sections are rarely exhaustive/unambiguous
- very difficult to re-create analyses without code
- e.g., is data trimming explicitly defined?
- this will even affect descriptive statistics
Reproducibility rates in linguistic research

- meta-analysis of 519 randomly sampled articles from various linguistic journales
- pre- and post-reproducibility crisis (2008/9, 2018/19) (Bochynska et al., 2023)
- differentiated between primary (collected for study) and secondary (pre-existing) data
- reported a post-RC increase in shared materials, data, and analyses
- but still low rates of each
- higher rates of secondary data sharing, presumably due to publicly available corpora
- data shared more often than analyses, pre- and post-RC
Journal of Memory and Language
- meta-analysis of articles from JML (Laurinavichyute et al., 2022)
- before and after an Open Science Policy was introduced in 2019
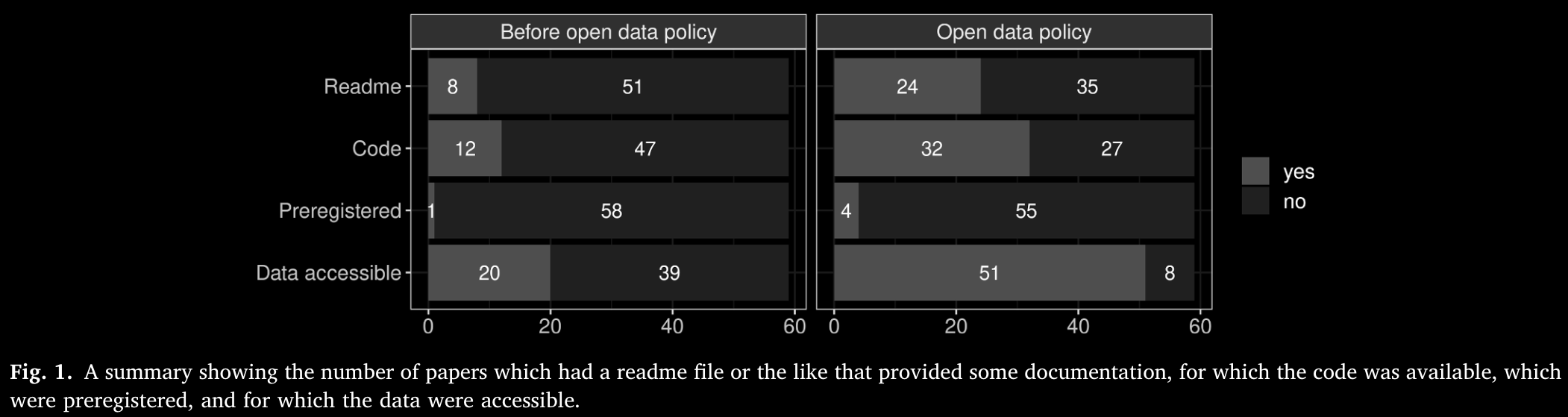
Figure 6: Source: Laurinavichyute et al. (2022), p. 5 (all rights reserved)
- code and data availability improved
- but reproducibility rate ranged from 34-56%, depending on criteria
- higher rates compared to field-wide meta-analysis (Bochynska et al., 2023)